Модуль random позволяет добавить в ваши программы немного случайности. В этой статье мы разберемся, зачем и как им пользоваться.
Основы random
По сути, модуль random позволяет генерировать псевдослучайные числа. В его основе лежит функция random(). Она основана на вихре Мерсенна, быстром и надежном алгоритме. В то же время, алгоритм не является криптографически стойким — для шифрования лучше использовать специализированные модули. Сама функция написана на С и генерирует числа с плавающей точкой от 0 до 1.
import random
random.random()
# 0.08129688364234133
В некоторых случаях, нам важно в точности воспроизвести результаты генератора. Для этого можно инициализировать генератор последовательностью бит. По умолчанию, инициализация происходит на основании системного времени. Также можно записать состояние генератора, и устанавливать его при необходимости.
# Инициализируем генератор:
random.seed(‘okumy`)
random.random()
# 0.9256099337339457
# Записываем состояние:
s = random.getstate()
random.random()
# 0.17970329300977872
# Устанавливаем состояние:
random.setstate(s)
random.random()
# 0.17970329300977872
Работа с целыми числами
Для генерации случайного числа в диапазоне используется randint(a, b) или randrange(start, stop[, step]). Обратите внимание, что значение stop не включается в диапазон.
random.randint(1, 6) # 6
random.randrange(0, 101, 25) # 50
random.randrange(0, 101) # 23
Работа с последовательностями
Выбрать случайный элемент из последовательности позволяет функция choice(seq)
s = ‘OKUMY’
random.choice(s)
# Y
Функция choices((population, weights=None, *, cum_weights=None, k=1)) позволяет отобрать k случайных элементов из последовательности. Учитывайте, что они могут повторяться.
s = [True, False]
choices(s, k=4)
# [True True False True]
Более того, элементам можно назначить веса — вероятности их выбора. За это отвечает аргумент weights. Аналогично, cum_weights устанавливает кумулятивные веса, что удобно для работы с ранжированными данными.
d = {
‘a’: 0,
‘b’: 0,
‘c’: 0
}
for i in random.choices(
[*d.keys()],
weights=[10, 80, 10],
k=100
):
d[i] += 1
print(d)
# {‘a’: 8, ‘b’: 80, ‘c’: 12}
Функция shuffle(seq) перемешивает изменяемые последовательности.
s = [1, 2, 3, 4]
random.shuffle(s)
print(s)
# [1, 2, 4, 3]
Для работы с неизменяемыми последовательностями удобнее функция sample(population, k, *, counts=None), создающая выборки. Чтобы получить результат аналогичный shuffle(seq), достаточно указать k=len(seq). Аргумент counts позволяет указать число повторов для каждого элемента. Например, random.sample(‘AB’, [2, 3]) эквивалентно random.sample(‘AABBB’).
s = ‘OKUMY’
random.sample(s, k=3)
# [‘O’, ‘U’, ‘M’]’
Другие распределения
Существуют разнообразные распределения вероятностей, используемые не только в статистике, но и в других областях. Например, распределение Гаусса (Нормальное распределение) описывает огромное множество случайных процессов, от погрешности измерений до экологических законов. Экспоненциальное распределение широко применяется в физике.
Настраивая параметры функций модуля random, можно получить множество самых разнообразных распределений, описывающих вероятности большинства процессов. Вот некоторые из них.
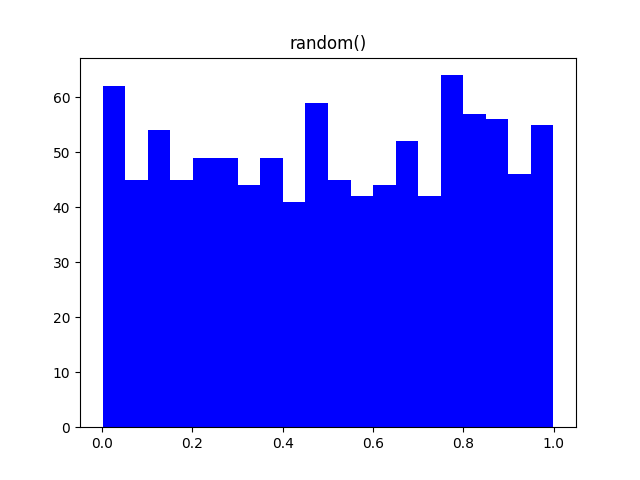
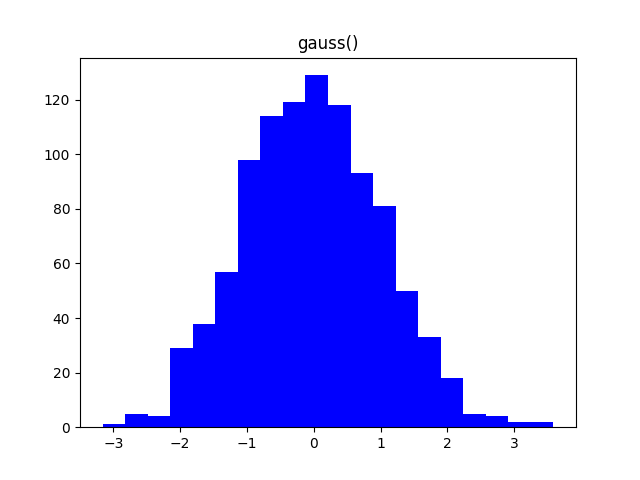
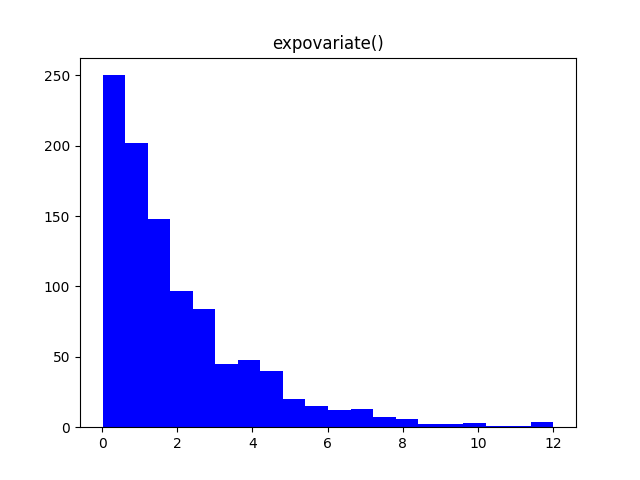
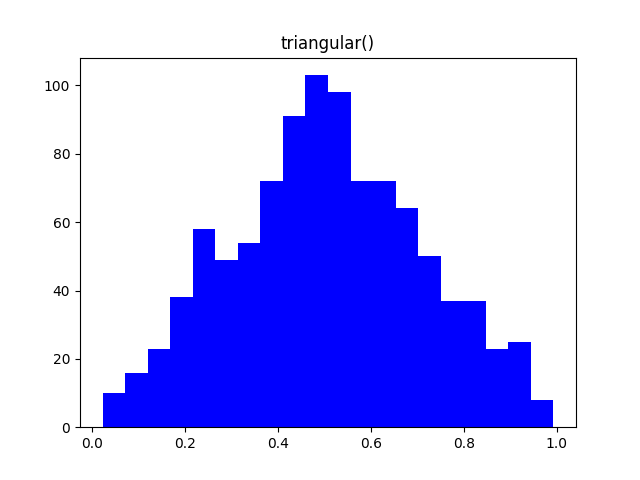
Заключение
Модуль random — один из самых полезных в стандартной библиотеке. Он позволяет генерировать случайные числа, перемешивать последовательности и отбирать из них случайные элементы. Он может использовать разные распределения вероятностей, что может пригодиться для моделирования естественных процессов. Возможность инициализировать генераторы одинаковым сидом и манипулировать состоянием генератора позволяют воспроизводить результаты выполнения программ, что полезно при разработке и тестировании.